Column Directive
Column directive allows instruction of a data source and modification of its presentation. Column directives are defined relative to the table that they are part of. They can be used in visible-columns or a visible-foreign-keys annotation.
In Overall structure we briefly explain different methods of defining a column directive.
In Shorthand syntax we mention the alternative and simpler way of defining column directives.
Using Properties section you can find all the available properties in column directive.
Please Find the examples in this section.
Table of contents
-
1. Column directive with source
2. Column directive with sourcekey
3. Column directive without any source
-
1. Data source properties
2. Presentation properties
3. Condition properties
condition_key
Overall structure
As it was described, column directives are meant to intruct the data source and its presentation. Based on how the data source is defined, we can categorize them into the following:
1. Column directive with source
In this category, you use the source property to define the data source of the column directive in place. Other source related properties (i.e. entity, aggregate) can be used in combination with source to change the nature of the column directive. The following is an overview of such column directive with all the available properties (some might not be applicaple depending on where the column directive is used):
{
"source" : <source path>,
"entity": <true or false>,
"aggregate": <aggregate function>,
"self_link": <boolean>
"markdown_name": <display name>,
"comment": <tooltip message>,
"comment_display": <inline|tooltip>,
"comment_render_markdown": <boolean>,
"hide_column_header": <boolean>,
"visible_cell_height": <number or false>,
"display": {
"markdown_pattern": <pattern>,
"template_engine": <handlebars or mustache>,
"wait_for": <wait_for list>,
"show_foreign_key_link": <boolean>,
"show_key_link": <boolean>,
"array_ux_mode": <csv|ulist|olist|raw>,
"selector_ux_mode": <facet-search-popup|simple-search-dropdown>,
"required": <boolean>
},
"array_options": {
"order": <change the default order>,
"max_lengh": <max length>
},
"input_iframe": {
"url_pattern": <pattern>,
"field_mapping": <object>,
"optional_fields": <array of field names>
},
"condition": {
"sourcekey": <source key for condition data>,
"source": <source path for condition data>,
"on_empty": <"show" or "hide">,
"condition_pattern": <pattern>,
"template_engine": <handlebars or mustache>,
"wait_for": <wait_for list>
},
"condition_key": <condition key>
}
2. Column directive with sourcekey
In this category, the sourcekey proprety is used to refer to one of the defines sources in the source-definitions annotations. The following is an overview of such column directive with all the available properties (some might not be applicaple depending on where the column directive is used):
{
"sourcekey" : <source key>,
"entity": <true or false>,
"aggregate": <aggregate function>,
"self_link": <boolean>,
"markdown_name": <display name>,
"comment": <tooltip message>,
"comment_display": <inline|tooltip>,
"comment_render_markdown": <boolean>,
"hide_column_header": <boolean>,
"visible_cell_height": <number or false>,
"display": {
"markdown_pattern": <pattern>,
"template_engine": <handlebars or mustache>,
"wait_for": <wait_for list>,
"show_foreign_key_link": <boolean>,
"show_key_link": <boolean>,
"array_ux_mode": <csv|ulist|olist|raw>,
"selector_ux_mode": <facet-search-popup|simple-search-dropdown>,
"required": <boolean>
},
"array_options":{
"order": <change the default order>,
"max_lengh": <max length>
},
"condition": {
"sourcekey": <source key for condition data>,
"source": <source path for condition data>,
"on_empty": <"show" or "hide">,
"condition_pattern": <pattern>,
"template_engine": <handlebars or mustache>,
"wait_for": <wait_for list>
},
"condition_key": <condition key>
}
3. Column directive without any source
If you want to have a column directive that its value is made up of multiple column directives, you don’t need to define any source or sourcekey. The only required attributes for these types of columns (we call them virtual columns) are markdown_name that is used for generating the display name, and markdown_pattern under display to get the value. For instance the following is an acceptable virtual column:
{
"markdown_name": "displayname value",
"display": {
"markdown_pattern": "{{{column1}}}, {{{column2}}}"
}
}
In order to access the data of other column directives in this virtual column, you can use the wait_for option.
The following is an overview of such column directive with all the available properties (some might not be applicaple depending on where the column directive is used):
{
"markdown_name": <display name>,
"comment": <tooltip message>,
"comment_display": <inline|tooltip>,
"hide_column_header": <boolean>,
"visible_cell_height": <number or false>,
"display": {
"markdown_pattern": <pattern>,
"template_engine": <handlebars or mustache>,
"wait_for": <wait_for list>
}
}
Properties
Some properties are only available in special scenarios and are not used in all the scenarios. As you can see in the overall structure, there are three different ways that you can define a column directive:
1. Data source properties
These sets of properties change the nature of the column directive, as they will affect the communication with server. To detect duplicate column-directives we only look for these attributes. The properties are:
These attribute will also dictate the default display heuristics that are used for the column. For instance if it’s an aggregate, it will require an extra request and will therefore modify the heuristics for displaying the values.
source
This property allows the definition of “source path”. As column directive is define on a table, it can either be
One of the current table’s column.
A column in table that has a valid foreign key relationship with the current table.
Even if the column directive is used in “entity” mode where it’s suppsoed to represent the row and not just a column, we must record this column choice explicitly in the column directive so that we can use an unambiguous column while communicating with ERMrest.
Therefore the following are acceptable ways of defining source path:
A column name string literal (an array of one string is also acceptable):
{"source": "column"} {"source": ["column"]}
An array of path element that ends with a columnname that will be projected and filtered.
[path element, ... ,columnname]
Each anterior element MAY use one of the following sub-document structures:
{ "sourcekey":sourcekey prefix}Only acceptable as the first element. Please refer to source path with reusable prefix for more information.
sourcekey prefix is a string literal that refers to any of the defined sources in
source-definitionsannotations
{direction:fkeyname}Links a new table instance to the existing path via join.
direction can either be
"inbound", or"outbound".fkeyname is the given name of the foreign key which is usually in the following format:
[schema name,constraint name]
{ "and": [filter,…], "negate":negate}A logical conjunction of multiple filter clauses is applied to the query to constrain matching rows.
The logical result is negated only if negate is
true.Each filter clause may be a terminal filter element, conjunction, or disjunction.
This syntax cannot be used with all-outbound paths or local columns in a non-
filtercontext.
{ "or": [filter,…], "negate":negate}A logical disjunction of multiple filter clauses is applied to the query to constrain matching rows.
The logical result is negated only if negate is
true.Each filter clause may be a terminal filter element, conjunction, or disjunction.
This syntax cannot be used with all-outbound paths or local columns in a non-
filtercontext.
{ "filter":column, "operand_pattern":value, "operator":operator, "negate":negate}An individual filter path element is applied to the query or individual filter clauses participate in a conjunction or disjunction.
The filter constrains a named column in the current context table.
The value specifies the constant operand for a binary constraint operator and must be computed to a non-empty value.
Pattern expansion MAY be used to access the pre-defined values in templating envorinment. In
detailedcontext, you may also access the main table data or foreign key values.Like other pattern expansions, the default
template_enginewill be applied and if you want to change it, you can definetemplate_enginealongside theoperand_pattern.
The operator specifies the constraint operator via one of the valid operator names in the ERMrest REST API, which are
| operator | meaning |
|-----------|---------|
| `::null::`| column is `null` |
| `=` | column equals value |
| `::lt::` | column less than value |
| `::leq::` | column less than or equal to value |
| `::gt::` | column greater than value |
| `::geq::` | column greater than or equal to value |
| `::regexp::` | column matches regular expression value |
| `::ciregexp::` | column matches regular expression value case-insensitively |
| `::ts::` | column matches text-search query value |
> If `operator` is missing, we will use `=` by default.
- The logical result of the constraint is negated only if _negate_ is `true`.
- This syntax cannot be used with all-outbound paths or local columns in a non-`filter` context.
The following are some examples of defining source path:
[{"inbound": ["S1", "FK1"]}, "Column2"]
[{"inbound": ["S1", "FK1"]}, {"outbound": ["S2", "FK2"]}, "Column3"]
[{"sourcekey": "path_to_f1"}, {"outbound": ["S2", "FK2"]}, "Column3"]
[{"sourcekey": "path_to_f2"}, "Column3"]
[{"inbound": ["S1", "FK1"]}, {"filter": "RCB", "operand_pattern": "{{{$session.client.id}}}"}, "Column3"]
Source path with reusable prefix
In some cases, the defined foreign key paths for different columns/facets might be sharing the same prefix. In those cases, reusing the prefix allows sharing certain joined table instances rather than introducing more “copies” as each facet is activated which in turn will increase the performance.
To do this, you would have to use 2019:source-definitions annotation and define the shared prefix. Then you can use sourcekey to refer to this shared prefix in the source path.
When using a prefix, the prefix’s last column and all the other extra attributes on it will be ignored for the purpose of prefix.
You can use recursive prefixes. If we detect a circular dependency, we’re going to invalidate the given definition.
While using prefix, you MUST add extra foreign key paths to the relationship. The following is not an acceptable source:
[ {"sourcekey": "path_2"}, "RID" ]
Since our goal is to reuse the join instance as much as we can, all-outbound foreign keys can also share the same join instances.
For example, assume the following is the ERD of table:
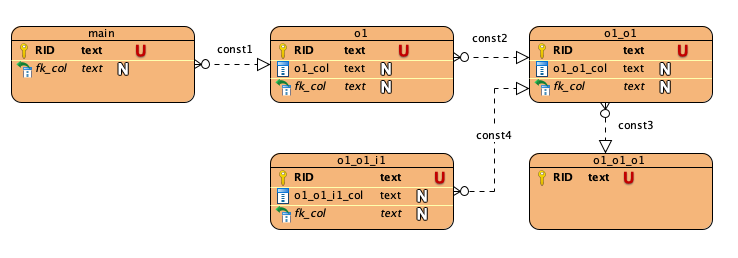
And the following is source-definition and visible-columns annotation:
"tag:isrd.isi.edu,2019:source-definitions`": {
"sources": {
"path_to_o1": {
"source": [
{"outbound": ["schema", "const1"]},
"o1_col"
]
},
"path_to_o1_o1": {
"source": [
{"sourcekey": "path_to_path_prefix_o1"},
{"outbound": ["schema", "const2"]},
"o1_o1_col"
]
}
}
},
"tag:isrd.isi.edu,2016:visible-columns": {
"compact": [
"id",
{
"sourcekey": "path_to_o1",
},
{
"sourcekey": "path_to_o1_o1",
},
{
"source": [
{"sourcekey": "path_to_o1"},
{"outbound": ["schema", "const3"]},
"o1_o1_o1_col"
]
}
]
}
Then this is a valid facet blob:
{
"and": [
{
"source": [
{"sourcekey": "path_to_o1_o1"},
{"inbound": ["faceting_schema", "const4"]},
"o1_o1_i1_col"
],
"choices": ["v1"]
},
{
"sourcekey": "path_to_o1_o1",
"choices": ["v2"]
}
]
}
Which is roughly translated to the following ERMrest query:
M:=schema:main/
M_P2:=(fk_col)=(schema:o1:RID)/M_P1:=(fk_col)=(schema:o1_o1:RID)/
(RID)=(schema:o1_o1_i1:fk_col)/o1_o1_i1_col=v1/$M/
$M_P1/o1_o1_col=v2/$M/
$M_P1/F3:=left(fk_col)=(schema:o1_o1_o1:RID)/$M/
RID;M:=array_d(M:*),F3:=array_d(F3:*),F2:=array_d(M_P1:*),F1:=array_d(M_P2:*)@sort(RID)
sourcekey
Instead of defining a column directive in place, you can define them in the source-definitions annotations, and refer to those definitions using sourcekey. You can also use this property to refer to an existing source definition and modify the display or data source attributes (apart from source) for this instance.
entity
If the column directive can be treated as entity (the column that is defined in source path is key of the table), setting entity attribute to false will force the scalar mode. This will affect different logic and heuristics. In a nutshell, entity-mode means we try to provide a UX around a set of entities (table rows). Scalar mode means we try to provide a UX around a set of values like strings, integers, etc.
"entity": false
aggregate
This is only applicable in visible columns definition (Not applicable in Facet definition). You can use this attribute to get aggregate values instead of a table. The available functions are cnt, cnt_d, max, min, array, and array_d.
minandmaxare only applicable in scalar mode.arraywill return ALL the values including duplicates associated with the specified columns. For data types that are sortable (e.g integer, text), the values will be sorted alphabetically or numerically. Otherwise, it displays values in the order that it receives from ERMrest. There is no paging mechanism to limit what’s shown in the aggregate column, therefore please USE WITH CARE as it can incur performance overhead and ugly presentation.array_dwill return the distinct values. It has the same performance overhead asarray, so pleas USE WITH CARE.
2. Presentation properties
The following attributes can be used to manipulate the presentation settings of the column directive.
markdown_name
markdown_name captures the display name of the column. You can change the default display name by setting the markdown_name attribute.
"markdown_name": "**new name**"
comment
In Chaise, comment is displayed as tooltip associated with columns. To change the default tooltip for the columns, the comment attribute can be used.
"comment": "New comment"
comment_display
By default Chaise will display comment as a tooltip. Set this value to inline to show it as text or tooltip to show as a hover tooltip.
inline comments are only supported in the following scenarios:
visible-foreign-keysannotation indetailedcontext (related entities).visible-columnsannotation indetailedcontext.visible-columnsannotation inentrycontexts.
hide_column_header
By setting this to true, chaise will hide the column header (and still show the value). This is only supported in detailed context. If this attribute is missing, we are going to use the inherited behavior from the column display annotation. If that one is missing too, display annotation will be used.
visible_cell_height
Limit the height of displayed cells. Currently only supported in the detailed context (record page). The acceptable values are,
Any positive number (in pixels): The cell values in the record page will be limited to the given height.
300is the recommended starting value for most content.false: Disable the feature and show all the contents. If this property is missing or is invalid, this is the default behavior.
self-link
If you want to show a self-link to the current row, you need to make sure the source is based on a not-null unique column of the current table and add the "self_link": true to the definition.
display
By using this attribute you can customize the presented value to the users. The following is the accepted syntax:
{
...,
"display": {
"markdown_pattern": <markdown pattern value>,
"template_engine": <"handlebars" | "mustache">,
"wait_for": <wait_for list>,
"show_foreign_key_link": <boolean>,
"show_key_link": <boolean>
"array_ux_mode": <csv|ulist|olist|raw>,
"selector_ux_mode": <facet-search-popup|simple-search-dropdown>
}
}
markdown_pattern
Allows modification of the displayed values for the column directive. You can access the current column directive data with $self namespace alongside the defined source definitions. Please refer to the Column directive display documentation for more information.
Notes:
If a value that is not a string or an empty string is provided for this property, we will ignore that. And act as if this property was completely missing.
wait_for
Used to signal Chaise that this column directive’s markdown_pattern relies on the values of other column directives. It’s an array of sourcekeys that are defined in the source-definitions annotation of the table. You should list all the all-outbound, aggregates, and entity sets that you want to use in your markdown_pattern. Entity sets (column directives with inbound path and no aggregate attribute) are only acceptable in detailed context. Please refer to the column directive display documentation for more information.
show_foreign_key_link
While generating a default presentation for all outbound foreign key paths, ERMrestJS will display a link to the referred row. Using this attribute you can modify this behavior. If this attribute is missing, we are going to use the inherited behavior from the foreign key annotation defined on the last foreign key in the path. If that one is missing too, display annotation will be applied.
selector_ux_mode
While generating a default presentation in entry mode for single outbound foreign key paths, Chaise will show a modal popup dialog for selecting rows. Using this attribute, you can modify this behavior. If this attribute is missing, we are going to use the inherited behavior from the foreign key annotation defined on the foreign key relationship. If that one is missing too, table display annotation will be applied. Supported values are "facet-search-popup" and "simple-search-dropdown", with "facet-search-popup" being the default.
required
Use this property to force the required (nullok) check for this visible column. This property is only used in the entry contexts. If set to true, users cannot leave the input empty. And if set to false, the input becomes optional.
bulk_create_foreign_key
Use this property to control the bulk selection of foreign key values in entry/create context when there is a prefill query parameter. Supported values are a foreign key name in the format of ['schema_name', 'foreign_key_name'] from the schema document, false, or null. Using a foreign key name will use that foreign key as the one being bulk selected if that foreign key is in the visible columns list. false turns off the heuristics that trigger this feature. null will override inheritance for this property and use the default heuristics. This will override the bulk_create_foreign_key property defined in the display property of the foreign-key annotation. Currently only supported in entry/create context.
show_key_link
While generating a default presentation for key column directives (self link), ERMrestJS will add a link to the referred row. Using this attribute you can modify this behavior. If this attribute is missing, we are going to use the inherited behavior from the key display annotation. If that one is missing too, display annotation will be applied.
array_ux_mode
If you have "aggregate": "array" or "aggregate": "array_d" in your column directive definition, you can use array_ux_mode attribute to change the display of values. You can use
olistfor ordered bullet list.ulistfor unordered bullet list.csvfor comma-seperated values (the default presentation).rawfor space-seperated values.
array_options
If you have "aggregate": "array" or "aggregate": "array_d" in your column directive definition, you can use array_options to change the array of data that client will present. It will not have any effect on the generated ERMrest query and manipulation of the array is happening on the client side. The available options are:
order: An alternative sort method to apply when a client wants to semantically sort by key values. Its syntax is similar tocolumn_order.Assuming your path ends with column
col, the default order is{"column": "col", "descending": false}.In scalar mode, you can only sort based on the scalar value of the column (other table columns are not available). So you can only switch the sort from ascending to descending.
max_length: A number that defines the maximum number of elements that should be displayed. We are not going to apply any default value for this attribute. If you don’t provide anymax_length, we are going to show all the values that ERMrest returns.
{
"source": <a valid path in entity mode>,
"entity": true,
"aggregate": <array or array_d>,
"array_options": {
"order": [
{
"column": <a column in the projected table>,
"descending": <boolean value>,
},
{
"column": <another column in the projected table>,
"descending": <boolean value>,
},
...
],
"max_length": <number>
}
},
{
"source": <a valid path in scalar mode>,
"entity": false,
"aggregate": <array or array_d>,
"array_options": {
"order": [
{
"column": <the scalar projected column>,
"descending": <boolean value>,
}
],
"max_length": <number>
}
}
input_iframe
This property can be used for integrating Chaise’s recordedit app with any third-party tools. When this property is added to a visible column in entry contexts, Chaise will display a special input for them. Clicking on this input will open a modal to show the third-party tool in an iframe.
For more information about this property, please refer to this document.
3. Condition properties
These properties allow you to conditionally show or hide a column or related entity. There are two forms:
With source (
sourceorsourcekeyset): The condition is based on the result of a separate data source. Useful when visibility depends on whether related data exists. With-source conditions are evaluated only in thedetailedcontext (record page); they are ignored incompact,entry,filter, etc.No source (only
condition_patternset, nosource/sourcekey/wait_for): The condition is a pure template evaluated synchronously against the catalog’s template environment. Useful for ACL-driven visibility, for example showing a column only to members of a given group. No-source conditions are honored in every context, includingcompact,entry, andfilter(facets).
condition
A JSON object that defines an inline condition controlling whether this column or related entity is displayed. The object has the following properties:
sourcekey: (optional) A string referencing one of the sources defined in thesource-definitionsannotation. The data returned by this source is used to evaluate the condition.source: (optional) An inline source path (same syntax as the column directive source property). Use this as an alternative tosourcekeywhen you don’t need to reuse the condition source elsewhere. If bothsourceandsourcekeyare provided,sourcekeytakes precedence.on_empty: (optional) Decides what to do when the condition result is “empty”. Applies to both with-source and no-source forms. Accepted values:"hide"(default): Hide the column when empty (show when non-empty)."show": Show the column when empty (hide when non-empty).
What counts as “empty” is determined by
condition_pattern(see below): if a pattern is set, “empty” means the rendered template is empty or whitespace-only; if no pattern is set (with-source only), “empty” means the source returned no rows or a null/empty value.condition_pattern: (optional withsource/sourcekey; required without) A template whose rendered output determines visibility. When provided with a source, the template has access to$self(the condition source value) plus the same templating environment asmarkdown_pattern. When provided without a source, it is the entire condition: only the catalog-wide template environment is available (e.g.,$session,$catalog, and helpers likeisUserInAcl). No markdown rendering is applied to the result; only emptiness is checked.wait_for: (optional, only withsource/sourcekey) An array of source key strings (referencing sources defined insource-definitions). These sources are fetched alongside the condition source, and their data is available in the templating environment whencondition_patternis evaluated. The condition is not evaluated until allwait_forsources have completed. Not allowed for no-source conditions.
You must define at least one of source, sourcekey, or condition_pattern.
{
"source": "some_column",
"condition": {
"sourcekey": "has_related_items",
"on_empty": "hide"
}
}
Example with wait_for:
{
"source": "some_column",
"condition": {
"sourcekey": "count_of_items",
"wait_for": ["count_of_other_items"],
"condition_pattern": "{{#if (and count_of_other_items count_of_items)}}show{{/if}}",
"template_engine": "handlebars"
}
}
No-source example (ACL-driven visibility):
{
"source": "admin_notes",
"condition": {
"condition_pattern": "{{#if (isUserInAcl \"https://group-id-for-admins\")}}show{{/if}}",
"template_engine": "handlebars"
}
}
This column appears only when the current user is in the given group. Beyond isUserInAcl, condition_pattern in the no-source form can reference any of the pre-defined template variables ($session, $catalog, $moment, etc.) and any helper available in the templating environment.
How conditions are evaluated:
Visibility is a two-step decision: first determine whether the condition result is “empty”, then apply on_empty to decide show vs. hide.
Resolve the result. For with-source conditions, the client fetches the condition source data if it isn’t already available. For no-source conditions, nothing is fetched.
Decide if the result is “empty”. This depends on whether
condition_patternis set:Pattern set (either form): render the template; “empty” means the rendered output is empty or whitespace-only.
No pattern (with-source only): “empty” means the source returned no rows (for entity sets) or a null/empty value (for aggregates).
Apply
on_emptyto map “empty” to show vs. hide:"hide"(default): the column is shown only when the result is not empty."show": the column is shown only when the result is empty.
For example, a no-source condition_pattern of {{#if (isUserInAcl "admin")}}show{{/if}} renders non-empty for admins and empty for everyone else. With on_empty: "hide" (default), admins see the column; with on_empty: "show", the visibility is inverted (everyone except admins sees it).
Entity-set sources see only the first page:
When a with-source condition’s source is an entity set (an inbound path in entity mode, no aggregate), the condition is evaluated against the first page of that entity set, and it is evaluated once on load (it is not re-evaluated when the user paginates the related table). This is fine for a “does it have any rows” check, because the first page is empty exactly when the table is empty. It is not reliable for a condition_pattern that iterates $self looking for a specific row (for example “is there a row where term=one”) once the table can have more rows than the page size, because rows beyond the first page are not visible to the template. For a condition that must consider the whole table, use an aggregate source (for example a cnt with a filter) instead. The entity-set condition source exists to reuse the read that already happens to display the related table, so it does not widen the page or perform an unbounded read.
condition_key
A string that references a reusable condition defined in the conditions section of the source-definitions annotation. This allows you to define a condition once and apply it to multiple columns or related entities. The referenced condition can be either the with-source or no-source form, and the same context rules apply (with-source only in detailed; no-source in every context).
If both condition and condition_key are defined on the same column directive, condition_key takes precedence and condition is ignored.
{
"source": "some_column",
"condition_key": "has_related_data"
}
Where has_related_data is defined in the source-definitions annotation:
"tag:isrd.isi.edu,2019:source-definitions": {
"sources": {
"cnt_related": {
"source": [{"inbound": ["schema", "fk1"]}, "RID"],
"aggregate": "cnt"
}
},
"conditions": {
"has_related_data": {
"sourcekey": "cnt_related"
}
}
}
Shorthand syntax
While the general syntax of column directives is defining a JSON object, depending on where the column directive is used, you can use the shorthand syntax which heavily relies on heuristics. The following are other acceptable ways of defining column directives:
In read-only non-filter context of
visible-columnsannotation, you can use string to refer to any of the columns in the table. For instance the two following syntax are alternative to each other:{ "source": "column" }
"column"In non-filter context of
visible-columnsannotation you can use the two-element list of string literal which identifies a constituent foreign key of the table. The value of the external entity referenced by the foreign key will be presented, with representation guided by other annotations or heuristics. Therefore the follow are alternative:{ "source": [ {"outbound": ["schema", "fkey1"]}, "RID" ], "entity": true }
["schema", "fkey1"]
In
detailedcontext ofvisible-columnsandvisible-foreign-keysannotation you can use the two-element list of string literal which identifies a constituent foreign key that is referring to the current table (inbound relationship). Therefore the follow are alternative:{ "source": [ {"inbound": ["schema", "fkey_to_main"]}, "RID" ], "entity": true }
["schema", "fkey_to_main"]
In
detailedcontext ofvisible-columnsandvisible-foreign-keysannotation you can use the two-element list of string literal which identifies a constituent foreign key from a pure and binary association table to the current table. Therefore the follow are alternative:{ "source": [ {"inbound": ["schema", "fkey_from_assoc_to_main"]}, {"outbound": ["schema", "fkey_from_assoc_to_related"]}, "RID" ], "entity": true }
["schema", "fkey_from_assoc_to_main"]
In read-only non-filter context of
visible-columnsannotation you can use the two-element list of string literal which identifies a constituent key of the table. The defined display of the key will be presented, with a link to the current displayed row of data. This is the same as theself_linkproperty on column directive JSON object. Therefore the follow are alternative:{ "source": "RID", "entity": true "self_link": true }
["schema", "primary_key"]
Examples
Let’s assume the following is the ERD of our database. In all the examples we’re defining column list for the Main table (assuming S is the schema name).
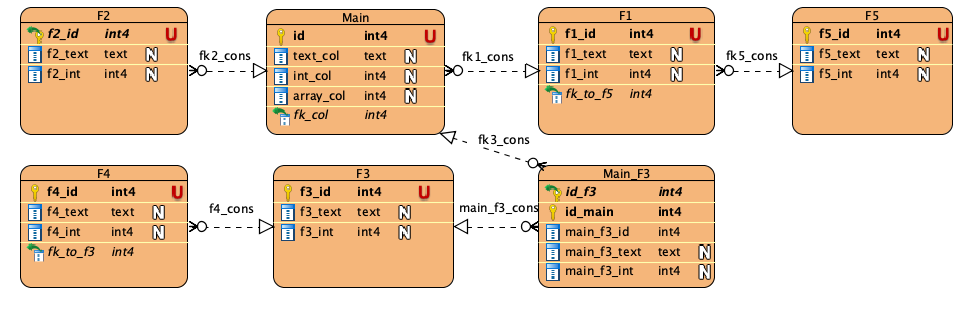
Visible Column List
The following summarizes the different types of columns and syntaxes that are acceptable:
| Type | General Syntax | Shorthand Syntax | Acceptable Contexts | Behavior |
|---|---|---|---|---|
| Normal Columns | {"source": "id"} |
"id" |
All | |
| Asset Columns | {"souce": "asset_col"} |
"asset_col" (assuming asset_col is a column with asset annotation) |
All | dl button in read-only upload in edit mode |
| Key Columns | {"source": "id", "entity": true, "self_link": true} |
["s", "key_cons"] |
read-only | self-link |
| ForeignKey Columns | {"source": [{"outbound": ["s", "fk1_cons"]}, "f1_id"], "entity": true} |
["s", "fk1_cons"] |
All | Link to row in read-only Modal picker in edit mode |
| Inbound ForeignKey Columns | {"source": [{"inbound": ["s", "fk2_cons"]}, "f2_id"], "entity": true} |
["s", "fk2_cons"] |
detailed | Inline Table |
| Associative Inbound ForeignKey Columns | {"source": [{"inbound": ["s", "fk3_cons"]}, {"outbound": ["s", "main_f3_cons"]}, "f3_id"], "entity": true} |
["s", "fk3_cons"] |
detailed | Inline Table |
| inline table (entity mode with inbound) | {"source": <any acceptable source with inbound in path and in entity mode>, "entity": true} |
N.A. | detailed | Inline Table |
| Aggregate | {"source": <any acceptable source>, "aggregate": } |
N.A. | read-only | Aggregated value |
| All outbound entity path | {"source": <any acceptable source with only outbound>, "entity": true} |
N.A. | read-only | entity mode: link to row scalar mode: scalar value |
Other examples:
To show scalar values of a foreignkey column in the main table:
{"source": [{"outbound": ["S", "fk1_cons"]}, "f1_text"]}
{"source": [{"outbound": ["S", "fk1_cons"]}, "f1_id"], "entity": false}
To show link to a row that main has foreignkey to.
{"source": [{"outbound": ["S", "fk1_cons"]}, "f1_id"], "entity": false}
To show list (table) of related entities:
{"source": [{"inbound": ["S", "fk3_cons"]}, "main_f3_id"]}
{"source": [{"inbound": ["S", "fk3_cons"]}, {"outbound": ["S", "main_f3_cons"]}, "f3_id"]}
{"source": [{"inbound": ["S", "fk3_cons"]}, {"outbound": ["S", "main_f3_cons"]}, {"inbound": ["S", "f4_cons"]}, "f4_id"]}
To show aggregate values:
{"source": [{"inbound": ["S", "fk3_cons"]}, "main_f3_id"], "aggregate": "cnt_d"}
{"source": [{"inbound": ["S", "fk3_cons"]}, {"outbound": ["S", "main_f3_cons"]}, "f3_id"], "aggregate": "array", "array_display": "olist"}
{"source": [{"inbound": ["S", "fk3_cons"]}, {"outbound": ["S", "main_f3_cons"]}, {"inbound": ["S", "f4_cons"]}, "f4_id"], "entity": false, "aggregate": "min"}
Visible ForeignKey List
{"source": [{"inbound": ["S", "fk3_cons"]}, "main_f3_id"]}
{"source": [{"inbound": ["S", "fk3_cons"]}, {"outbound": ["S", "main_f3_cons"]}, "f3_id"]}
{"source": [{"inbound": ["S", "fk3_cons"]}, {"outbound": ["S", "main_f3_cons"]}, {"inbound": ["S", "f4_cons"]}, "f4_id"]}
Alternative syntax
As we mentioned, you can define the specific column directive using the general syntax. If you use the both syntax, one of them will be ignored (the one that comes first in the column list will be used. The following are examples of alternative ways of defining column directive that are only acceptable in visible-columns and visible-foreign-keys:
Foreign key:
["S", "fk1_cons"] == {"source":[ {"outbound": ["S", "fk1_cons"]}, "f1_id" ]}
["S", "fk1_cons"] =/= {"source":[ {"outbound": ["S", "fk1_cons"]}, "f1_id" ], "entity": false}
["S", "fk1_cons"] =/= {"source":[ {"outbound": ["S", "fk1_cons"]}, "f1_text" ]}
Inbound foreign key:
["S", "fk2_cons"] == {"source":[ {"inbound": ["S", "fk2_cons"]}, "f2_id"]}
["S", "fk3_cons"] == {"source":[ {"inbound": ["S", "fk3_cons"]}, {"outbound": ["S", "main_f3_cons"]}, "f3_id"}
["S", "fk3_cons"] =/= {"source":[ {"inbound": ["S", "fk3_cons"]}, "main_f3_id"}
Key:
["S", "main_key_constraint"] == {"source": "id"}
["S", "main_key_constraint"] =/= {"source": "id", "entity": false}
comment_render_markdown
A boolean value that dictates whether the comment should be treated as markdown or not. If not defined, its value will be inherited from the underlying column or table which could be inherited from the schema or the catalog. If it’s not defined on any of the models, the default behavior is to treat comments as markdown.
This boolean works independent of the
commentproperty. Which means that you can definecommen_render_markdownto be used in combination with the comment that is derived based on the heuristics.